
1、一种通用的声音分类算法yamnet,框图如下:
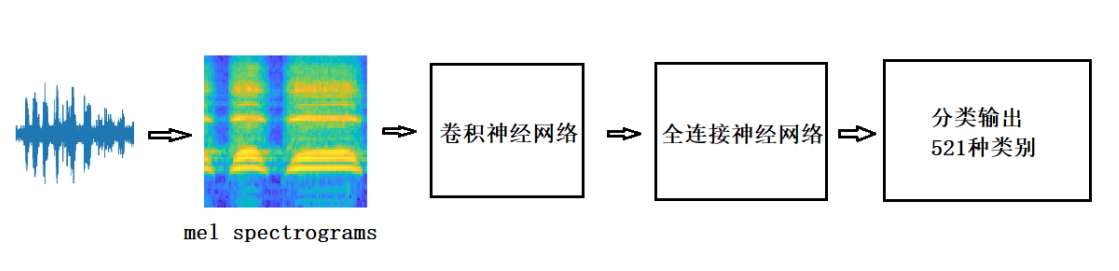
所有音频均重采样为 16 kHz 单声道,通过长度 25 毫秒,步长为 10 毫秒,且具有周期性 Hann 时间窗的短时距傅里叶变换计算出声谱图,通过将声谱图映射到覆盖 125 至 7500 Hz 范围的 64 个梅尔仓计算出梅尔声谱图,然后将这些特征分帧成具有 50%重叠且长度为0.96秒的示例,每个示例覆盖64个梅尔频段,总共 96 帧,每帧 10 毫秒,将96*64的梅尔声谱图输入神经网络,神经网络有卷积神经网络和全连接神经网络组成,总共86层,参数3.7M。
2、一种通用的语音活动检测神经网络,框图如下:
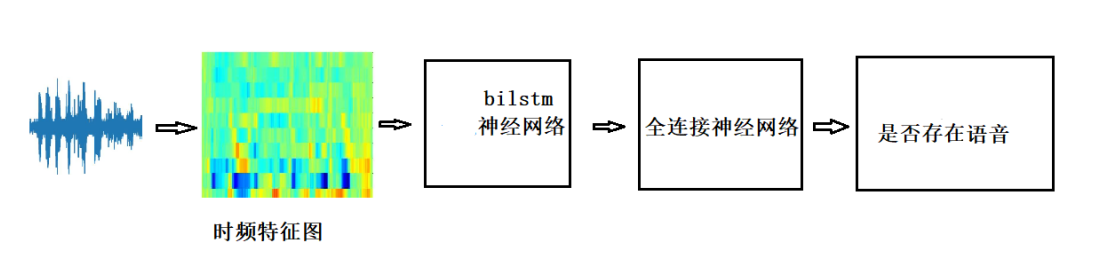
声音波形转换为时频特征图输入神经网络,神经网络有LSTM神经网络、全连接神经网络组成,总共100层,参数45k。
3、一种通用的关键词识别神经网络,框图如下:
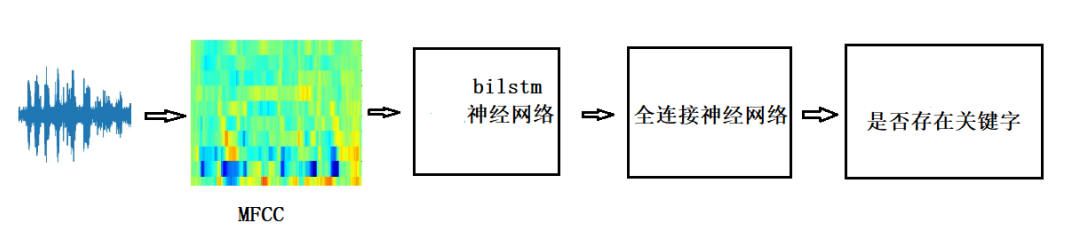
一个典型的关键字识别算法由一个特征提取器和一个基于神经网络的分类器组成,长度为 L 的输入语音信号被分成长度为 l 且步幅为 s 的重叠帧,总共有帧T帧。T=(L-l)/S+1从每一帧中提取 F 个语音特征,则长度为 L 的整个输入语音信号总共生成 T × F 个特征,Log-mel filter bank energies (LFBE) 和Mel-frequency cepstral coefficients (MFCC) 常用于基于深度学习的语音识别。将MFCC特征输入神经网络,神经网络有LSTM神经网络和全连接神经网络组成,总共30层,参数100k。
4、一种实时的单咪语音增强神经网络,框图如下:
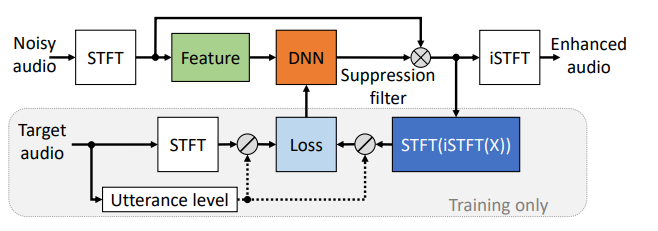
训练流程图
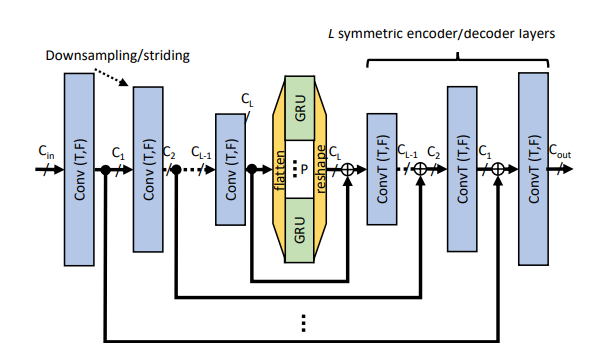
神经网络架构
5、一种通用的音频特征提取器vggish,框图如下:

将音频重采样为16kHz单声道音频,使用25ms的Hann时窗,10ms的帧移对音频进行短时傅里叶变换得到频谱图,通过将频谱图映射到64阶Mel滤波器组中计算Mel声谱,计算log(Mel-spectrum + 0.01),得到稳定的Mel声谱,所加的0.01的偏置是为了避免对0取对数。然后这些特征被以0.96s的时长被组帧,并且没有帧的重叠,每一帧都包含64个Mel频带,时长10ms(即总共96帧)。将96*64的梅尔声谱图输入神经网络,神经网络有卷积神经网络和全连接神经网络组成,总共24层,参数72M。